怎么爬微信数据库_微信群怎么快速爬楼梯
1.分析网页确定思路
我们这次准备爬取搜狗怎么爬微信数据库的微信搜索页面的结果,以风景为例怎么爬微信数据库:

可以看到这和我们之前爬取过的案例几乎类似,没什么新意,但是这里有一个比较神奇的地方就是10页以后的内容需要扫码登录微信才能查看

另外,在请求次数过多的时候还会出现封禁 ip 的情况,对应我们页面的状态码就是 出现 302 跳转
思路梳理怎么爬微信数据库:
(1)requests 请求目标站点,得到索引页的源码,返回结果
(2)如果遇到 302 则说明 ip 被封,切换代理后重试
(3)请求详情页,分析得到文章标题和内容
(4)将结构化数据保存到 MongoDB 数据库
注意点:
我们直接看浏览器的地址栏我们能看到很多的参数,但是实际上很大一部分是不需要的,那么为了我们的写代码的方便,我们尽量对参数进行简化,只留下最核心的参数
2.代码实现
config.py
# 数据库配置
MONGO_URL = 'localhost'
MONGO_DB = 'weixin'
MONGO_TABLE = 'articles'
#参数设置
KEYWORD = '风景'
MAX_COUNT = 5
BASE_URL = 'https://weixin.sogou.com/weixin?'
#代理设置
APP_KEY = ""
IP_PORT = 'transfer.mogumiao.com:9001'
PROXIES = {"http": "http://" + IP_PORT, "https": "https://" + IP_PORT}
HEADERS = {
'Cookie':'',
'Host':'weixin.sogou.com',
'Upgrade-Insecure-Requests':'1',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36',
'Proxy-Authorization': 'Basic '+ APP_KEY,
'Referer':'https://weixin.sogou.com/weixin'
}
spider.py

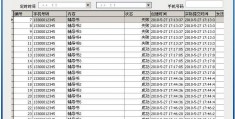
3.运行效果