

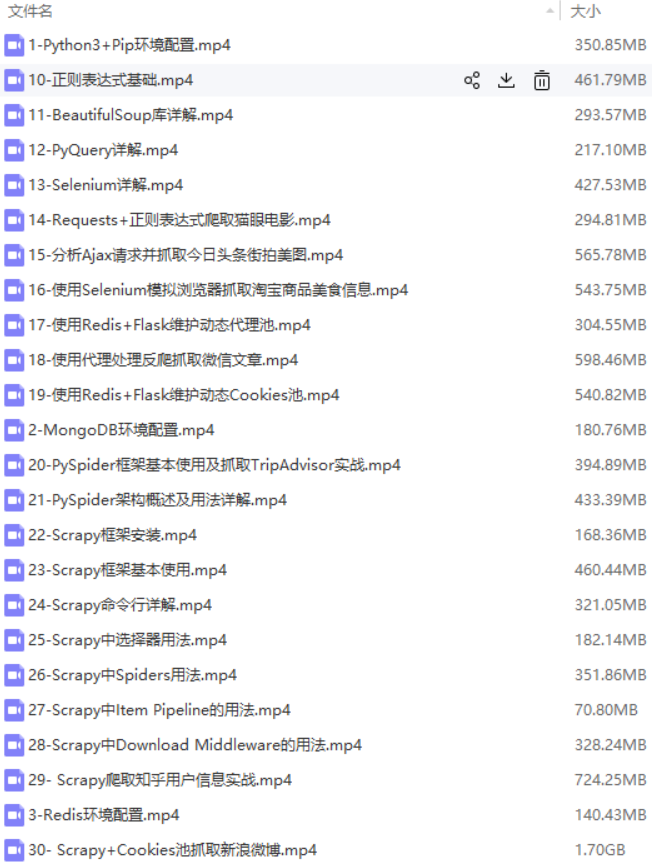
1- Python3+Pip环境配置
2- MongoDB环境配置
3- Redis环境配置
4- 4-MySQL的安装
5- 5-Python多版本共存配置
6- 6-Python爬虫常用库的安装
7- 7- 爬虫基本原理讲解
8- 8-Urllib库基本使用
9- 9-Requests库基本使用
10- 10-正则表达式基础
11- 11-BeautifulSoup库详解
12- 12-PyQuery详解
13- 13-Selenium详解
14- 14-Requests+正则表达式爬取猫眼电影
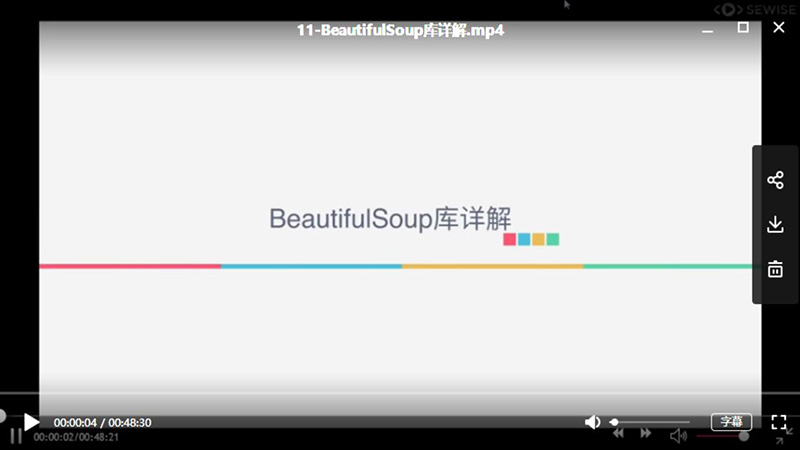
15- 15-分析Ajax请求并抓取今日头条街拍美图
16- 16-使用Selenium模拟浏览器抓取淘宝商品美食信息
17- 17-使用Redis+Flask维护动态代理池
18- 18-使用代理处理反爬抓取微信文章
19- 19-使用Redis+Flask维护动态Cookies池
20- 20-PySpider框架基本使用及抓取TripAdvisor实战
21- 21-PySpider架构概述及用法详解
22- 22-Scrapy框架安装
23- 23-Scrapy框架基本使用
24- 24-Scrapy命令行详解
25- 25-Scrapy中选择器用法
26- 26-Scrapy中Spiders用法
27- 27-Scrapy中Item Pipeline的用法
28- 28-Scrapy中Download Middleware的用法
29- 29- Scrapy爬取知乎用户信息实战
30- 30- Scrapy+Cookies池抓取新浪微博
31- 31-Scrapy+Tushare爬取微博股票数据
32- 32-Scrapy分布式原理及Scrapy-Redis源码解析
33- 33-Scrapy分布式架构搭建抓取知乎
34- 34-Scrapy分布式的部署详解


![[Python爬虫]---Python爬虫进阶项目实战](https://img.imahui.com/uploads/202005/10/T7dwY332589033849.jpg?x-oss-process=image/resize,m_mfit,h_380,w_500 "[Python爬虫]---Python爬虫进阶项目实战")


![[Python机器学习与量化交易]---量化交易项目班](https://img.imahui.com/uploads/202005/10/Bg3QR693095040140.jpg?x-oss-process=image/resize,w_290)

![[Python]---Python3.528期 基础进阶高级实战](https://img.imahui.com/uploads/202005/10/BULfc90396034149.png?x-oss-process=image/resize,w_290)
![[Python爬虫]---python分布式爬虫打造搜索引擎](https://img.imahui.com/uploads/202005/10/UXbKu197142033359.jpg?x-oss-process=image/resize,w_290)
![[Python爬虫]---分布式爬虫](https://img.imahui.com/uploads/202005/09/njfRc616262042846.jpg?x-oss-process=image/resize,w_290)
![[郝斌]C语言自学视频教程(共180集)](https://img.imahui.com/upvideo/20181206/1534733852205.jpg?x-oss-process=image/resize,w_290)



