c合并mdb数据库_多个mdb合成一个mdb
MDB是Tair系统中内置c合并mdb数据库的一款内存型KV存储引擎,在设计上,它采用内存池和page管理c合并mdb数据库的方式,使得它的的复杂度大大降低,实现的成本比较小,具备一定的实用性,不过简化的设计和实现,也带来了内存碎片、全局锁等问题和不足,这边文章里,我们主要对它的设计实现和不足之处进行一下总结,给感兴趣的同学一点参考。
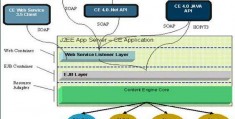
MD引擎设计
如上图所示,即为MDB内存存储引擎的核心设计和数据结构,刚开始时,引擎会分配一整块内存,然后按照固定大小(默认1M)切分为若干个page,每个page大小为1M,然后在这批page中把一部分page用来存储引擎的meta数据,主要的元数据包括:SlabManager、HashTable。
Slab Manager主要是管理若干个Slab,每个Slab的结构如上图所示,在内存分配时,Slab会把一个page按照固定的Item大小切分为若干个item,申请的时候直接返回page中item,它包含一些主要的字段:
per_slab:表示这个slab管理的page,固定切分成item的个数。full_pages_no:分配给该Slab的page中,无可用item的page个数。free_pages_no:分配给该Slab的page中,所有item完全可用的page个数。full_pages:full page的page id,表示无可用item的page的page id。free_pages:free_pages的page id,表示item完全可用的page id。partial_pages:它是一个数组,默认10个元素,用于存储item部分可用的page id,这个地方保存partial_pages id数组的原因是把partial_pages按照可用item个数排序,第一个表示即将要full占用的partial page id(比如可用item个数为1个,那么这个page排在第一个元素位置)。HashTable主要是把所有已分配的Item以Hash表的方式管理起来,它作为整个引擎所有索引,HashTable按照key进行hash取模,对应到其中一个bucket,然后将该key对应的item id存储到Hashtable中。这里有个实现上的小技巧,Hashtable中存储的都是item id,因为引擎内部根据item id就可以找到item,item中就存储了key-value的数据。
除了存储元数据的page之外,其c合并mdb数据库他的就是存储KV数据的page,每个page都包含一个page_info的头信息,用于存储page的元数据信息,里面的prev、next是把符合条件的pages组成一个链表。
Slab Manager

如上图所示,Slab Manager主要负责实际内存数据的分配,它有若干个Slab组成,每个Slab管理固定大小内存item的分配,举个例子说明,Slab Manager有100个Slab,第1个Slab管理80B大小的内存分配,第2个Slab管理80B*1.1大小的内存分配,依次类推,第100个Slab管理80B*1.1^99大小的内存分配。
当请求内存分配时,会先获取大于实际数据大小的第一个Slab,然后在这个Slab里分配一个固定大小的item,举个例子,当请求分配的key-value长度为70B,则直接选择第一个Slab进行内存分配。
在Slab中,保存有三种page:full page、free page、partial free page,它们都通过链表方式管理,Slab分配内存时,首先查找partial free page,找到则直接从一个partial free page中分配一个item,如果没有partial free page,则直接从free page中分配item,如果free page也没有,则从池子中选择一个空闲的pages,并从这个page里分配一个item。
HashTable

HashTable主要是用于管理所有item的索引,当通过slab manager分配成功一个item时,会将该item插入到hashtable中,首先对key做hash,映射到其中一个bucket,然后遍历该bucket的item列表,若key已经存在,则删除对应的item,然后再将新的item插入到对应bucket的列表头。
item中h_next用于HashTable的元素之间链接,而prev、next则用于page中free item链表的链接,page info中free_head保存着free item链表头,当从page中申请一个item时,直接从free_head链表头获取即可,提高item的分配效率。
回顾和分析前面的内容里主要介绍了MDB内存型KV存储引擎的设计和实现,由于内存池的分配机制,因为它的分配效率非常高,通过page、item的方式管理内存分配,使得实现的复杂度大大降低,但是,这也导致它存在一些风险和局限性,在生产环境常常会碰到一些问题,比如内存碎片、全局锁等。
内存碎片
每个page默认固定1M大小,系统分配时按照若干个固定大小分配内存,比如80B、80B*1.1、80B*1.1^2 ... ...,当申请内存时,按满足条件的第一个固定大小分配内存,比如申请70B内存,则实际分配的内存item大小为80B,存在一定的内存浪费,简化的设计虽然降低复杂度和成本,但与之同时一定也会带来其他的风险或问题。
在极端场景下,有可能空闲的内存为99%,实际只分配了1%的内存,但是系统再去申请内存的时候,有可能失败,这个问题的原因是因为Slab会管理所有已分配的page,有可能这些page全部都只分配了一个item,但是这些page全部都由这个Slab管理,比如某个Slab管理了所有page,这个Slab的分配大小为80B,那么程序再去申请80B*1.1的内存大小时会失败。
在实际生产环境中,虽然没有出现跟上述极端场景完全一样的问题,但也出现过上述类似的原因导致的内存分配失败,针对上述问题设计实现了Slab管理的page合并回收机制,大大提高了引擎可用性。
全局锁
引擎的所有读写共用一把大的互斥锁,这把锁成为了整个引擎的性能瓶颈点,因此,引擎的性能优化主要是针对这把锁展开的,在实际的生产环境中,推荐业务基本都是读多写少的场景,因此直接改用读写锁可以以最小的成本获取最大的收益。
从技术本身角度来讲,引擎性能优化还是得依赖于锁拆分,把全局锁拆分为多个线程安全的细粒度锁,在实际的生产环境中,由于节点的瓶颈是在内存空间大小上,实际的线上集群节点数能提供的性能远可以满足实际业务的性能需求,所以这个需求对业务而言属于重要不紧急需求,另一方面,也有人力资源不足的问题,这部分工作我们暂未落地,有兴趣的同学可以一起优化和改进该存储引擎。