非关系型数据库用法(关系型数据库)
编辑导语:通过ETL,我们可以将分散且凌乱非关系型数据库用法的数据整合到一起,进而帮助企业利用已有数据驱动决策。而ETL产品的关键点就在于抽取、转换与加载。具体应该如何设计一款ETL产品?本篇文章里,作者介绍了从0-1搭建ETL产品的策略 *** ,一起来看一下。

领导提了个小需求,公司做的系统越来越多了,数据也越来越多,想做一个属于公司内部的ETL工具做数据清洗并归集。你无从下手,或许本文可以帮助你。
一、ETL是什么?ETL( Extract-Load-Transform)是将业务系统的数据抽取到一个中间数据库里,在里面经过各种规则的转换之后,装载到数据仓库的过程。目的是将分散、凌乱、标准不统一的数据整合到一起,帮助企业将沉睡的数据最大价值利用起来。
一般常见的做法包括ETL或者ELT,一个是先抽取到中间库转换好后再装载到目标数据库,另一个是将数据抽取并装载到目的端,利用目的端的数据处理能力完成数据转换工作。
通常越大量的数据、复杂的转换逻辑、目的端为较强运算能力的数据库,越偏向使用ELT,以便运用目的端数据库的处理能力。
二、怎么设计ETL?其实这款产品的设计很简单,根据该产品的名称,我们就可以把功能模块分为三部分:抽取、转换、加载。
1. 功能点一:抽取设计数据抽取功能,需要解决几个问题:一是需要确定从哪些源系统进行数据抽取;二是数据抽取的 *** ,是主动抽取还是由源系统推送?是增量抽取还是全量抽取?三是数据抽取的频次,是按照每日抽取还是按照每月抽取。
1)数据库连接
首先我们需要把数据从业务系统中抽取出来,从哪些源系统抽取,就要知道这个源业务系统放数据的数据库是哪一个,想要人家的东西就要知道人家放东西的地址在哪,也就是数据库连接。
数据库的类型大致可分为三种:关系型数据库、非关系型数据库(NoSQL)、键值数据库,目前企业最常用的关系型数据库Oracle、MySQL,非关系型数据库BigTable、MongoDB等,可根据业务情况增添所需要的数据库种类。
 数据源名称:帮助用户在操作数据源连接时,给所连接的数据源起个名称,便于后续的选择使用;数据源描述:便于管理和记忆数据源的信息;数据库地址:想要连接数据库的地址;端口号:一台计算机可以提供多个服务,端口号就类似于这些服务的门牌号。例如:在一台电脑上,浏览网页服务、连接服务器服务、微信服务、钉钉服务等,每一项都对应一个端口号,只有通过这些端口号,客户端才能真正的访问到这些服务。MySQL端口号一般默认是3306;数据库名称:同一个数据库地址可以包括很多数据库,每个数据库都有自己的名字,每个数据库里面包含了很多张数据表;用户名和密码:由业务方来分配,非关系型数据库用法他们会把你可操作的数据权限放权给该账户。
数据源名称:帮助用户在操作数据源连接时,给所连接的数据源起个名称,便于后续的选择使用;数据源描述:便于管理和记忆数据源的信息;数据库地址:想要连接数据库的地址;端口号:一台计算机可以提供多个服务,端口号就类似于这些服务的门牌号。例如:在一台电脑上,浏览网页服务、连接服务器服务、微信服务、钉钉服务等,每一项都对应一个端口号,只有通过这些端口号,客户端才能真正的访问到这些服务。MySQL端口号一般默认是3306;数据库名称:同一个数据库地址可以包括很多数据库,每个数据库都有自己的名字,每个数据库里面包含了很多张数据表;用户名和密码:由业务方来分配,非关系型数据库用法他们会把你可操作的数据权限放权给该账户。通过这样几项内容的设计,用户就可以连接到一个确定的数据库,并使用里面的数据表。
数据库连接好之后,还需要连接测试一下是否能连通,以防因为网络或者信息填写错误等原因导致没有连上,那就是表面看着连好了,实际上是无效的数据库。

2)数据抽取
连接好源数据库后,就可以开始抽取工作了。这时需要解决刚提出的第二个问题,如何抽取?
ETL的工作一般都是主动抽取,能推送的话那就太好了,不过源系统推送的可能性不大,因为这增加了源业务方的工作量,本来抽取数据都会多多少少影响业务的运行情况,现在还来增加工作量,这不是给人家添堵嘛。所以不推送也没关系,能让主动抽就可以。
是增量抽取还是全量抽取呢?这个是根据业务需求而定,全量抽取比较好操作,每次做数据清洗任务时,把需要的表全部抽取过来就可以了。而增量抽取是只抽取新增部分的数据,要实现增量抽取,就要准确地捕获到数据库中数据源表的变化。
数据的变化无非是增、删、改,只要能监测到数据有这三种形式的变化,并对变化做一些处理,就能实现增量抽取了。增量抽取有四种方式:
① 触发器方式
在被抽取的数据源表上建立插入、修改、删除3个触发器,当源表中的数据发生变化(是新增、修改,还是删除了),可以指定一个或多个具备唯一性的字段来监测,对应的触发器就将变化的数据写入一个增量日志表,抽取时则从增量日志中抽取,同时,增量日志表中抽取过的数据要及时被标记或删除。
② 时间戳方式
增量抽取时,通过比较指定抽取时间与抽取源表的时间戳字段的值决定抽取哪些数据。这种方式需要在源表中增加一个时间戳字段,源表数据更新或修改时,同时也会修改时间戳字段的值,这样就知道源表发生了哪些变化,将变化的数据重新抽取即可。
③ 全表比对方式
增量抽取时,ETL任务会逐条比较源表和目标表的记录,将新增或修改等变化的记录过滤读取出来,这种方式就比较考验硬件环境了。
④ 日志表方式
在数据库中创建业务日志表,增量抽取时,通过读日志表数据决定加载哪些数据,日志表的维护需要由业务系统程序编写代码完成。
以上四种增量抽取方式没有一种方式具有绝对优势,不同的方式在不同的企业中表现大体平衡。通常根据企业的业务需求和硬件环境来选择。
根据这四种方式描述,可以看出,我们比较好设计到产品中的就是触发器方式、时间戳方式、全表比对方式。


3)任务调度
如果需求是按日、按周或者按月抽取数据,并执行清洗任务,怎么办呢?可以通过任务调度功能来实现。
任务调度功能的设计就是来自于cron表达式。cron,是计划任务,指在约定的时间执行已经计划好的工作,是用代码来实现任务调度的用法。
任务调度的运行频次一般包括分、时、日、周、月,为什么没有秒调度,这玩意儿要求太高了,比较耗费资源,能满足到分的定时任务就可以了。调度任务的配置逻辑就是任务在什么时间开始运行,多久运行一次,什么时间结束运行。
 2. 功能点二:转换
2. 功能点二:转换数据的清洗转换,主要任务是过滤掉不符合要求的数据,不符合要求的数据主要有不完整的数据、错误的数据、重复的数据三大类。
根据数据清洗的业务需求,在ETL产品中设计各种类型的清洗组件,在组件设置页面由用户配置清洗规则,完成数据清洗任务的设计。
例如,根据抽取、转换、加载的流程,组件可以分为三大类:输入、转换、输出。
输入组件包括数据表输入、Excel文件输入、SQL输入等;转换组件包括过滤、聚合、合并、排序、数据脱敏、增加计算字段、行转列等;输出组件包括数据表输出、Excel文件输出等。 3. 功能点三:加载
3. 功能点三:加载数据加载的主要任务是将数据从临时数据表或文件中加载到指定的数据仓库中。如果是全量方式则采用LOAD方式,如果是增量则根据业务规则,使用SQL语句MERGE进数据库。
对于一个ETL任务流,一般会在数据抽取时进行增量操作,将增量抽取的数据清洗之后再统一加载到目标表中。
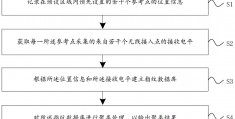
业务场景:抽取商品销售订单数据表,商品数据表,计算出每日的销售订单总金额并入库。
第一步: *** ETL任务流程,抽取商品销售订单数据,商品数据表,通过商品ID关联成一张表。

第二步:计算每日销售订单总金额。增加一个订单总金额字段,并添加计算公式订单总金额=订单金额*数量。

第三步:设置调度任务,定时执行ETL任务。选择运行频次“天”,设定任务在哪一段时间内执行,也可以指定几个不在这段时间内的单个时间执行任务。
 四、写在结尾
四、写在结尾本文只是教大家如何搭建一个ETL产品的基础功能,搭建出来的产品要能真正的上线使用起来,除了需要考虑到:产品运作流程要使用的方案,是ETL还是ELT?如果要与BI产品共同使用,如何与其交互?
还需要认真思考一下,我们到底需要什么样的ETL?只是想做数据采集,支撑数据仓库的建设,还是作为一个数据交换平台,赋予其更多的应用场景。
这些大家在设计产品的时候都要考虑清楚,和相关开发团队以及领导多讨论沟通,有疑问的地方欢迎留言。
本文由 @金豌豆 原创发布于人人都是产品经理,未经许可,禁止转载
题图来自Pexels,基于 CC0 协议