hive抽取数据库-hive和sql的区别
温馨提示:要看高清 *** 套图hive抽取数据库,请使用手机打开并单击图片放大查看。
Faysonhive抽取数据库的github:https://github.com/fayson/cdhproject
1.问题描述
在CDH集群中hive抽取数据库我们需要将Hive表的数据导入到RDBMS数据库中,使用Sqoop工具可以方便的将Hive表数据抽取到RDBMS数据库中,在使用Sqoop抽取Hive Parquet表时作业执行异常。
Sqoop抽数脚本:
sqoop export \
--connect jdbc:mysql://localhost:3306/test_db \
--username root \
--password 123456 \
--table mytest_parquet \
--export-dir /user/hive/warehouse/mytest_parquet \
-m 1
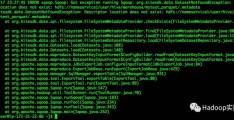
异常日志:
17/12/17 01:18:52 ERROR sqoop.Sqoop: Got exception running Sqoop: org.kitesdk.data.DatasetNotFoundException: Descriptor location does not exist: hdfs://nameservice1/user/hive/warehouse/mytest_parquet/.metadataorg.kitesdk.data.DatasetNotFoundException: Descriptor location does not exist: hdfs://nameservice1/user/hive/warehouse/mytest_parquet/.metadata at org.kitesdk.data.spi.filesystem.FileSystemMetadataProvider.checkExists(FileSystemMetadataProvider.java:562) at org.kitesdk.data.spi.filesystem.FileSystemMetadataProvider.find(FileSystemMetadataProvider.java:605) at org.kitesdk.data.spi.filesystem.FileSystemMetadataProvider.load(FileSystemMetadataProvider.java:114) at org.kitesdk.data.spi.filesystem.FileSystemDatasetRepository.load(FileSystemDatasetRepository.java:197) at org.kitesdk.data.Datasets.load(Datasets.java:108) at org.kitesdk.data.Datasets.load(Datasets.java:140) at org.kitesdk.data.mapreduce.DatasetKeyInputFormat$ConfigBuilder.readFrom(DatasetKeyInputFormat.java:92) at org.kitesdk.data.mapreduce.DatasetKeyInputFormat$ConfigBuilder.readFrom(DatasetKeyInputFormat.java:139) at org.apache.sqoop.mapreduce.JdbcExportJob.configureInputFormat(JdbcExportJob.java:84) at org.apache.sqoop.mapreduce.ExportJobBase.runExport(ExportJobBase.java:429) at org.apache.sqoop.manager.SqlManager.exportTable(SqlManager.java:931) at org.apache.sqoop.tool.ExportTool.exportTable(ExportTool.java:80) at org.apache.sqoop.tool.ExportTool.run(ExportTool.java:99) at org.apache.sqoop.Sqoop.run(Sqoop.java:147) at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70) at org.apache.sqoop.Sqoop.runSqoop(Sqoop.java:183) at org.apache.sqoop.Sqoop.runTool(Sqoop.java:234) at org.apache.sqoop.Sqoop.runTool(Sqoop.java:243) at org.apache.sqoop.Sqoop.main(Sqoop.java:252)[ec2-user@ip-172-31-22-86 ~]$
2.解决 ***
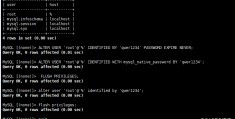
1.将Sqoop抽数脚本修改为如下:
sqoop export \--connect jdbc:mysql://ip-172-31-22-86.ap-southeast-1.compute.internal:3306/test_db \--username testuser \--password password \--table mytest_parquet \--hcatalog-database default \--hcatalog-table mytest_parquet --num-mappers 1参数说明:
--table:MySQL库中的表名
--hcatalog-database:Hive中的库名
--hcatalog-table:Hive库中的表名,需要抽数的表
--num-mappers:执行作业的Map数
2.修改后执行抽数作业

作业执行成功。

3.查看MySQL表数据
 3.总结
3.总结目前通过Sqoop从Hive的parquet抽数到关系型数据库的时候会报kitesdk找不到文件的错,这是Sqoop已知的问题,参考SQOOP-2907:
https://issues.apache.org/jira/browse/SQOOP-2907
该jira目前并没有修复,如果要实现该功能,需要参考第二章的做法,使用hcatalog参数指定到Hive表。
为天地立心,为生民立命,为往圣继绝学,为万世开太平。
温馨提示:要看高清 *** 套图,请使用手机打开并单击图片放大查看。
您可能还想看
安装
CENTOS6.5安装CDH5.12.1(一)
CENTOS6.5安装CDH5.12.1(二)
CENTOS7.2安装CDH5.10和Kudu1.2(一)
CENTOS7.2安装CDH5.10和Kudu1.2(二)
如何在CDH中安装Kudu&Spark2&Kafka
如何升级Cloudera Manager和CDH
如何卸载CDH(附一键卸载github源码)
如何迁移Cloudera Manager节点
如何在Windows Server2008搭建DNS服务并配置泛域名解析
安全
如何在CDH集群启用Kerberos
如何在Hue中使用Sentry
如何在CDH启用Kerberos的情况下安装及使用Sentry(一)
如何在CDH启用Kerberos的情况下安装及使用Sentry(二)
如何在CDH未启用认证的情况下安装及使用Sentry
如何使用Sentry管理Hive外部表权限
如何使用Sentry管理Hive外部表(补充)
如何在Kerberos与非Kerberos的CDH集群BDR不可用时复制数据
Windows Kerberos客户端配置并访问CDH
数据科学
如何在CDSW中使用R绘制直方图
如何使用Python Impyla客户端连接Hive和Impala
如何在CDH集群安装Anaconda&搭建Python私有源
如何使用CDSW在CDH中分布式运行所有R代码
如何使用CDSW在CDH集群通过sparklyr提交R的Spark作业
如何使用R连接Hive与Impala
如何在Redhat中安装R的包及搭建R的私有源
如何在Redhat中配置R环境
什么是sparklyr
其hive抽取数据库他
CDH网络要求(Lenovo参考架构)
大数据售前的中年危机
如何实现CDH元数据库MySQL的主备
如何在CDH中使用HPLSQL实现存储过程
如何在Hive&Impala中使用UDF
Hive多分隔符支持示例
推荐关注Hadoop实操,第一时间,分享更多Hadoop干货,欢迎转发和分享。

原创文章,欢迎转载,转载请注明:转载自微信公众号Hadoop实操