数据库经常一致性错误(数据库事务的一致性)
缓存存储数据库经常一致性错误,也是数据的冗余。
数据库访问数据,磁盘IO,慢;缓存里访问数据,存操作,快;数据库里的热数据,可在缓存冗余一份;先访问缓存,如果存在,能大大的提升访问速度,降低数据库压力;这些,是缓存的核心读加速原理。
但是,一旦没有缓存,或者一旦涉及写操作,流程会比没有缓存更加复杂,今天我们就来解决这个问题
我们今天解决的问题为什么数据库和缓存中的数据会不一致不一致优化思路如何保证数据库与缓存的一致性我们的方式一、假设先写数据库,再淘汰缓存

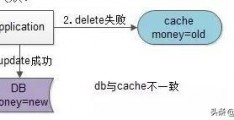
假设先写数据库,再淘汰缓存数据库经常一致性错误:第一步写数据库操作成功,第二步淘汰缓存失败,则会出现DB中是新数据,Cache中是旧数据,数据不一致【如上图:db中是新数据,cache中是旧数据】。

二、假设先淘汰缓存,再写数据库:
第一步淘汰缓存成功,第二步写数据库失败,则只会引发一次Cache miss【如上图:cache中无数据,db中是旧数据】。
结论:先淘汰缓存,再写数据库。
引发大家热烈讨论的点是“先操作缓存,在写数据库成功之前,如果有读请求发生,可能导致旧数据入缓存,引发数据不一致”,这就是本文要讨论的主题。
如何解决上面的问题写流程
(1)先淘汰cache
(2)再写db
读流程
(1)先读cache,如果数据命中hit则返回
(2)如果数据未命中miss则读db
(3)将db中读取出来的数据入缓存
什么情况下可能出现缓存和数据库中数据不一致呢?

在分布式环境下,数据的读写都是并发的,上游有多个应用,通过一个服务的多个部署(为了保证可用性,一定是部署多份的),对同一个数据进行读写,在数据库层面并发的读写并不能保证完成顺序,也就是说后发出的读请求很可能先完成(读出脏数据):
(a)发生了写请求A,A的第一步淘汰了cache(如上图中的1)
(b)A的第二步写数据库,发出修改请求(如上图中的2)
(c)发生了读请求B,B的第一步读取cache,发现cache中是空的(如上图中的步骤3)
(d)B的第二步读取数据库,发出读取请求,此时A的第二步写数据还没完成,读出了一个脏数据放入cache(如上图中的步骤4)
即在数据库层面,后发出的请求4比先发出的请求2先完成了,读出了脏数据,脏数据又入了缓存,缓存与数据库中的数据不一致出现了
不一致优化思路能否做到先发出的请求一定先执行完成呢?常见的思路是“串行化”,今天将和大家一起探讨“串行化”这个点。
先一起细看一下,在一个服务中,并发的多个读写SQL一般是怎么执行的

上图是一个service服务的上下游及服务内部详细展开,细节如下:
service的上游是多个业务应用,上游发起请求对同一个数据并发的进行读写操作,上例中并发进行了一个uid=1的余额修改(写)操作与uid=1的余额查询(读)操作service的下游是数据库DB,假设只读写一个DB中间是服务层service,它又分为了这么几个部分提问:任务队列其实已经做了任务串行化的工作,能否保证任务不并发执行?
答:不行,因为
(1)1个服务有多个工作线程,串行弹出的任务会被并行执行
(2)1个服务有多个数据库连接,每个工作线程获取不同的数据库连接会在DB层面并发执行
提问:假设1个服务只有1条数据库连接,能否保证任务不并发执行?
答:不行,因为
(1)1个服务只有1条数据库连接,只能保证在一个服务器上的请求在数据库层面是串行执行的
(2)因为服务是分布式部署的,多个服务上的请求在数据库层面仍可能是并发执行的
提问:假设服务只部署一份,且1个服务只有1条连接,能否保证任务不并发执行?
答:可以,全局来看请求是串行执行的,吞吐量很低,并且服务无法保证可用性
完了,看似无望了,
1)任务队列不能保证串行化
2)单服务多数据库连接不能保证串行化
3)多服务单数据库连接不能保证串行化
4)单服务单数据库连接可能保证串行化,但吞吐量级低,且不能保证服务的可用性,几乎不可行,那是否还有解?
退一步想,其实不需要让全局的请求串行化,而只需要“让同一个数据的访问能串行化”就行。
在一个服务内,如何做到“让同一个数据的访问串行化”,只需要“让同一个数据的访问通过同一条DB连接执行”就行。
如何做到“让同一个数据的访问通过同一条DB连接执行”,只需要“在DB连接池层面稍微修改,按数据取连接即可”
获取DB连接的CPool.GetDBConnection()【返回任何一个可用DB连接】改CPool.GetDBConnection(longid)【返回id取模相关联的DB连接】
这个修改的好处是:
(1)简单,只需要修改DB连接池实现,以及DB连接获取处
(2)连接池的修改不需要关注业务,传入的id是什么含义连接池不关注,直接按照id取模返回DB连接即可
(3)可以适用多种业务场景,取用户数据业务传入user-id取连接,取订单数据业务传入order-id取连接即可
这样的话,就能够保证同一个数据例如uid在数据库层面的执行一定是串行的
稍等稍等,服务可是部署了很多份的,上述方案只能保证同一个数据在一个服务上的访问,在DB层面的执行是串行化的,实际上服务是分布式部署的,在全局范围内的访问仍是并行的,怎么解决呢?能不能做到同一个数据的访问一定落到同一个服务呢?
能否做到同一个数据的访问落在同一个服务上?上面分析了服务层service的上下游及内部结构,再一起看一下应用层上下游及内部结构
上图是一个业务应用的上下游及服务内部详细展开,细节如下:
(1)业务应用的上游不确定是啥,可能是直接是http请求,可能也是一个服务的上游调用
(2)业务应用的下游是多个服务service
(3)中间是业务应用,它又分为了这么几个部分
(3.1)最上层是任务队列【或许web-server例如tomcat帮你干了这个事情了】
(3.2)中间是工作线程【或许web-server的工作线程或者cgi工作线程帮你干了线程分派这个事情了】,每个工作线程完成实际的业务任务,典型的工作任务是通过服务连接池进行RPC调用
(3.3)最下层是服务连接池,所有的RPC调用都是通过服务连接池往下游服务去发包执行的
工作线程的典型工作流是这样的:
voidwork_thread_routine(){
Task t = TaskQueue.pop(); // 获取任务
// 任务逻辑处理,组成一个网络包packet,调用下游RPC接口
ServiceConnection c = CPool.GetServiceConnection(); // 从Service连接池获取一个Service连接
c.Send(packet); // 通过Service连接发送报文执行RPC请求
CPool.PutServiceConnection(c); // 将Service连接放回Service连接池
}
似曾相识吧?没错,只要对服务连接池进行少量改动:
获取Service连接的CPool.GetServiceConnection()【返回任何一个可用Service连接】改为
CPool.GetServiceConnection(longid)【返回id取模相关联的Service连接】
这样的话,就能够保证同一个数据例如uid的请求落到同一个服务Service上。
总结由于数据库层面的读写并发,引发的数据库与缓存数据不一致的问题(本质是后发生的读请求先返回了),可能通过两个小的改动解决:
(1)修改服务Service连接池,id取模选取服务连接,能够保证同一个数据的读写都落在同一个后端服务上
(2)修改数据库DB连接池,id取模选取DB连接,能够保证同一个数据的读写在数据库层面是串行的
遗留问题提问:取模访问服务是否会影响服务的可用性?
答:不会,当有下游服务挂掉的时候,服务连接池能够检测到连接的可用性,取模时要把不可用的服务连接排除掉。
提问:取模访问服务与取模访问DB,是否会影响各连接上请求的负载均衡?
答:不会,只要数据访问id是均衡的,从全局来看,由id取模获取各连接的概率也是均等的,即负载是均衡的。