flume采集数据库_flume数据采集

一、Flumeflume采集数据库的介绍flume采集数据库:
Flume由Cloudera公司开发,是一种提供高可用、高可靠、分布式海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于采集数据;同时,flume提供对数据进行简单处理,并写到各种数据接收方的能力,如果能用一句话概括Flume,那么Flume是实时采集日志的数据采集引擎。
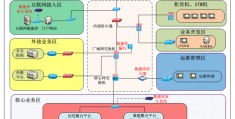
二、Flume的体系结构:

Flume的体系结构分成三个部分:数据源、Flume、目的地
数据源种类有很多:可以来自directory、http、kafka等,flume提供flume采集数据库了source组件用来采集数据源。
1、source作用:采集日志
source种类:1、spooling directory source:采集目录中的日志
2、htttp source:采集http中的日志
3、kafka source:采集kafka中的日志
……
采集到的日志需要进行缓存,flume提供了channel组件用来缓存数据。
2、channel作用:缓存日志
channel种类:1、memory channel:缓存到内存中(最常用)
2、JDBC channel:通过JDBC缓存到关系型数据库中
3、kafka channel:缓存到kafka中
……
缓存的数据最终需要进行保存,flume提供了sink组件用来保存数据。
3、sink作用:保存日志
sink种类:1、HDFS sink:保存到HDFS中
2、HBase sink:保存到HBase中
3、Hive sink:保存到Hive中
4、kafka sink:保存到kafka中
……
官网中有flume各个组件不同种类的列举:

三、安装和配置Flume:
1、安装:tar -zxvf apache-flume-1.7.0-bin.tar.gz -C ~/training
2、创建配置文件a4.conf:定义agent,定义source、channel、sink并组装起来,定义生成日志文件的条件。
以下是a4.conf配置文件中的内容,其中定义了数据源来自目录、数据缓存到内存中,数据最终保存到HDFS中,并且定义了生成日志文件的条件:日志文件大小达到128M或者经过60秒生成日志文件。
#定义agent名, source、channel、sink的名称
a4.sources = r1
a4.channels = c1
a4.sinks = k1
#具体定义source
a4.sources.r1.type = spooldir
a4.sources.r1.spoolDir = /root/training/logs
#具体定义channel
a4.channels.c1.type = memory
a4.channels.c1.capacity = 10000
a4.channels.c1.transactionCapacity = 100
#定义拦截器,为消息添加时间戳
a4.sources.r1.interceptors = i1
a4.sources.r1.interceptors.i1.type = org.apache.flume.interceptor.TimestampInterceptor$Builder
#具体定义sink
a4.sinks.k1.type = hdfs
a4.sinks.k1.hdfs.path = hdfs://192.168.157.11:9000/flume/%Y%m%d
a4.sinks.k1.hdfs.filePrefix = events-
a4.sinks.k1.hdfs.fileType = DataStream
#不按照条数生成文件
a4.sinks.k1.hdfs.rollCount = 0
#HDFS上的文件达到128M时生成一个日志文件
a4.sinks.k1.hdfs.rollSize = 134217728
#HDFS上的文件达到60秒生成一个日志文件
a4.sinks.k1.hdfs.rollInterval = 60
#组装source、channel、sink
a4.sources.r1.channels = c1
a4.sinks.k1.channel = c1
四、使用Flume语句采集数据:
1、创建目录,用于保存日志:
mkdir /root/training/logs
2、启动Flume,准备实时采集日志:
bin/flume-ng.agent -n a4 -f myagent/a4.conf -c conf -Dflume.root.logger=INFO.console
3、将日志导入到目录中:
cp * ~/training/logs
五、Sqoop和Flume的相同点和不同点:
相同点:sqoop和flume只有一种安装模式,不存在本地模式、集群模式等。
不同点:sqoop批量采集数据,flume实时采集数据。
作者:李金泽AllenLi,清华大学在读硕士,研究方向:大数据和人工智能